하둡 고가용성 클러스터 구축
Projects | | Links: Repository

정보전산원에 IP 할당 요청하고, Azure사에 문의해 Windows Server Datacenter OS 지원 받은 것부터 시작한 온프레미스 인프라 구축 경험.
프로젝트 요약
🕜 기간 : 2022.12 ~ 2023.06
👪 참여인력 : 개인
[하드웨어]
총 7개의 노드(Namenode 2, Datanode 5) 구성, 가상환경으로 Hyper-V를 사용.
각 노드는 dual-core vCPU, 16GB memory, 80GB storage로 구성. 또한, 1Gbps 네트워크로 연결됨.
[소프트웨어]
| Host | Windows Server 2022 Datacenter |
| Node | Ubuntu Server 22.04 LTS |
| Framework | Hadoop 3.3.5, Spark 3.4.0, Zookeeper 3.8.0, Zeppelin 0.10.1 |
| Programming Language | Java 1.8.0, Scala 2.12.17, Python 3.10.6 |
- HDFS, YARN의 고가용성을 위해 2개의 Namenode로 구성하였으며, Quorum Journal Manager, Zookeeper 사용.
- Spark, Hadoop Web UI를 사용하여 애플리케이션 작업 모니터링.
- Azure Arc, Azure Monitor를 사용한 인프라 리소스 모니터링.
- NAS를 활용하여 주기적인 서버백업.
프로젝트 목적
하둡 클러스터 환경에서 추천 시스템에 사용되는 기법 중 하나인 빈발 패턴 마이닝을 스파크를 활용하여 사용하는 방법에 관한 연구를 위해 프로젝트를 진행하였고, 성능 및 리소스 사용 측면에서 개선된 방법을 제안하는 것을 프로젝트의 목표로 하였습니다.
프로젝트 회고
하둡을 선택한 이유는?
현재 대용량의 데이터를 처리하기 위한 빅데이터 플랫폼과 분산처리 기술은 Hadoop-ecosystem 외에도 여러 선택지가 있습니다. 그럼에도 불구하고, 제가 Hadoop-ecosystem을 활용한 이유는 다음과 같습니다.
- 클라우드 서비스 사용에 대한 비용부담
- 이전에 경험한 기술의 숙련도를 높히고 보완 및 개선
- 밑바닥부터 시작하여 조금씩 고도화시키는 경험
우선, 클라우드 서비스 제공업체를 이용하는 것은 저한테 비용적인 부담이 컸습니다. 또한, 특정 클라우드 플랫폼에 종속되는 것이 아니라 자유롭게 컴퓨팅 자원을 활용하여 학습을 하고 싶은 마음이 있었습니다. 그리고 2020년도에 경험한 하둡 클러스터 환경을 전반적으로 보완 및 개선하고 싶어, 온프레미스 환경에서 오픈소스를 활용하여 하둡-에코시스템을 구축해 보는 것을 선택하게 되었습니다.
2020년도와 비교할때 개선된 점
2020년도 데이터엔지니어링 수업에서 하둡을 처음 접할 당시, 4개의 노드로 구성된 환경에서 실습을 진행하였습니다. 이때와 비교하면, 본 프로젝트는 아래와 같은 개선이 이뤄졌습니다.
| 노드 수 | 4개 => 7개 |
| Namenode | 1개 => 2개 |
| Version | Hadoop(2.X), … => Hadoop(3.3.5),… |
4개의 노드에서, 3개의 노드를 추가한 총 7개의 노드로 환경을 구성하였습니다. 그리고 Namenode의 수를 1개에서 2개로 확장하고 HDFS, YARN 고가용성 구성을 하여, 페일오버 상황에서도 애플리케이션이 무중단 운영이 가능하도록 하였습니다.
하드웨어 구성 선택 이유
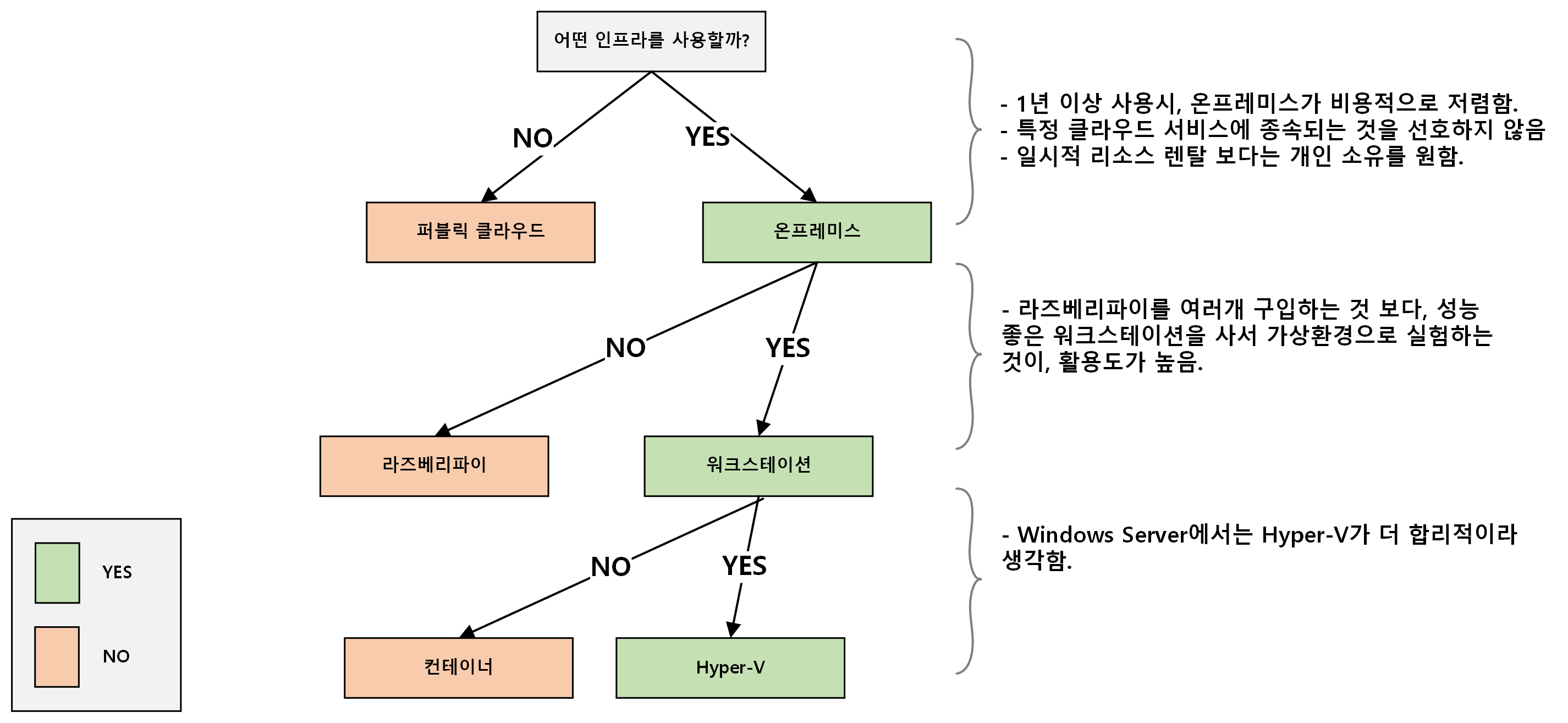
<그림 1> 하드웨어 구성 선택 이유
‘어떤 인프라 환경에서 프로젝트를 진행할까?‘라는 생각을 많이 했던 것 같습니다.
클라우드 서비스를 활용하는 것이 초기에는 이점이 많을 것이라 생각하지만, 저는 특정 클라우드 서비스를 활용하는 것에 능숙해지는 것 보다 해당 기술에 관한 깊은 이해를 하고 싶어, 온프레미스 환경을 구축하여 프로젝트를 진행하였습니다.
트러블 슈팅 방식 ⭐
최신 버전의 Hadoop, Spark 등의 오픈소스를 활용하여 프로젝트를 진행하였습니다. 이에 따라, 에러가 발생하는 상황에 레퍼런스를 찾기 어려운 경우가 종종 있었습니다.
프로젝트 초기에는 이해가 어려운 문제들을 해결하기 위해 가상머신을 여러 차례 삭제하고 처음부터 다시 시작하는 과정을 반복했습니다. 그러던 중 점차 노하우가 쌓여 가상머신을 단계적으로 스냅샷으로 저장하고, 문제가 발생하면 해당 스냅샷으로 복구하고 다른 시도 방법을 테스트하며 트러블 슈팅을 진행했습니다. 이 과정에서 에러 로그를 확인하고, 테스트를 진행하며 문제를 해결하려 노력했습니다. 해결이 어려운 경우에는 주로 공식문서, Stack Overflow를 참고하였으며, 구글에 검색하여 자료를 찾기 힘든 경우, 검색 엔진을 변경하여 다시 검색해보기도 했습니다. 또한, 도움이 필요한 경우 교수님이나 현직자들에게 질문을 하며 다양한 의견을 수렴하고 관점을 바꿔가며 트러블 슈팅을 진행했습니다.
치명적인 장애 해결 경험 ⭐
YARN 리소스 매니저가 Spark 애플리케이션 마스터 노드를 선정하고, 해당 노드와 조율을 통해 워커노드를 할당하는 과정에서 애플리케이션이 실패되는 치명적인 문제가 발생한적 있습니다.
결국, 문제의 직접적인 해결은 못 하였지만 YARN 리소스 매니저가 애플리케이션을 실패하는 경우에 Standby 노드의 YARN 리소스 매니저가 애플리케이션 Job을 수행하도록 하여 문제를 해결한 경험이 있습니다.
해당 에러 로그를 확인하기 위해 Spark 애플리케이션 Job을 WebUI로 확인하려 했으나, 애플리케이션이 종료된 이후에는 WebUI로 확인이 안된다는 문제가 있었습니다. 이를 해결하기 위해 Spark History Server를 구성하여 애플리케이션이 종료된 이후에도 로그를 확인할 수 있도록 개선한 경험이 있습니다.
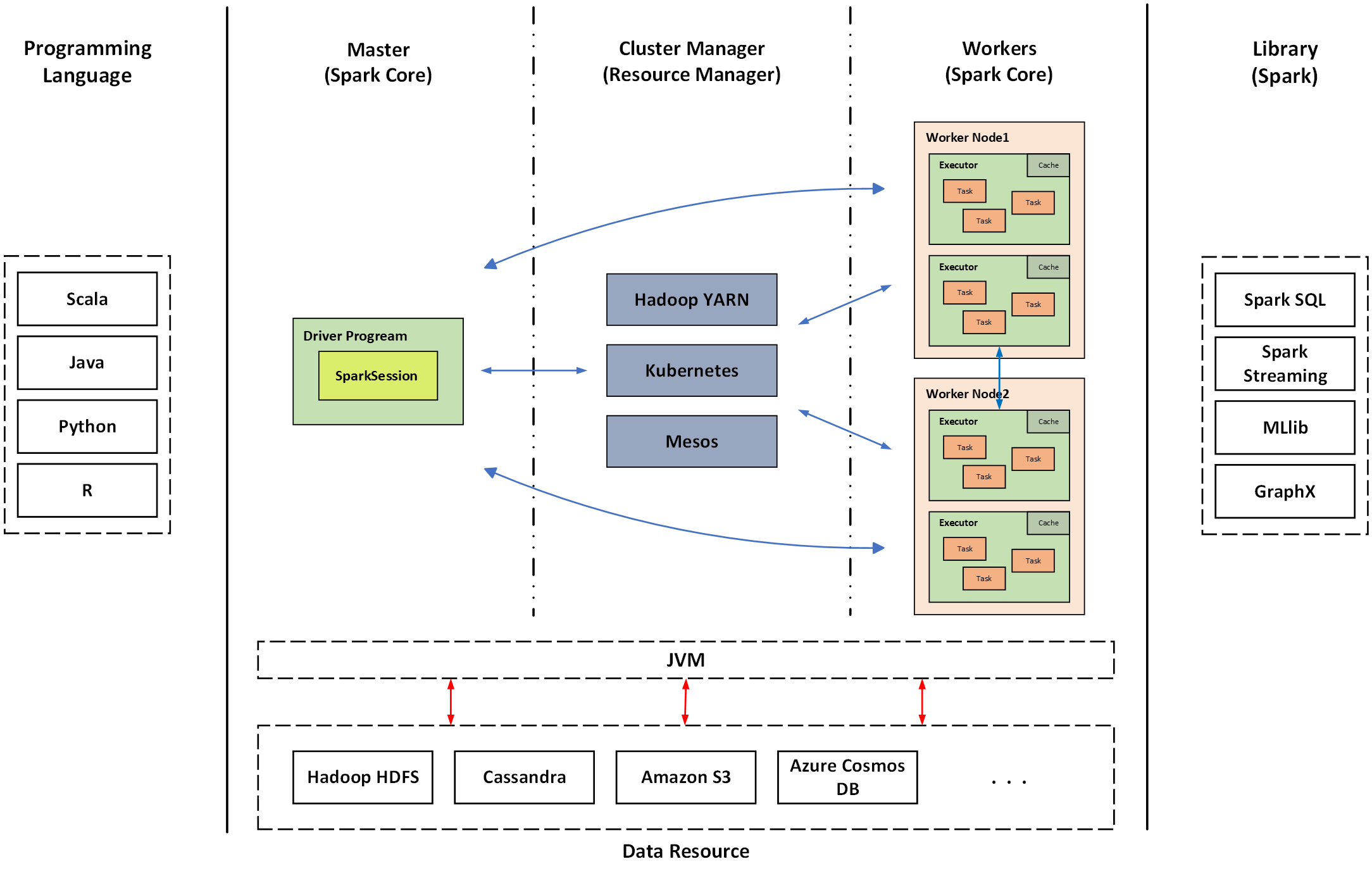
<그림 2> Spark 클러스터 개요
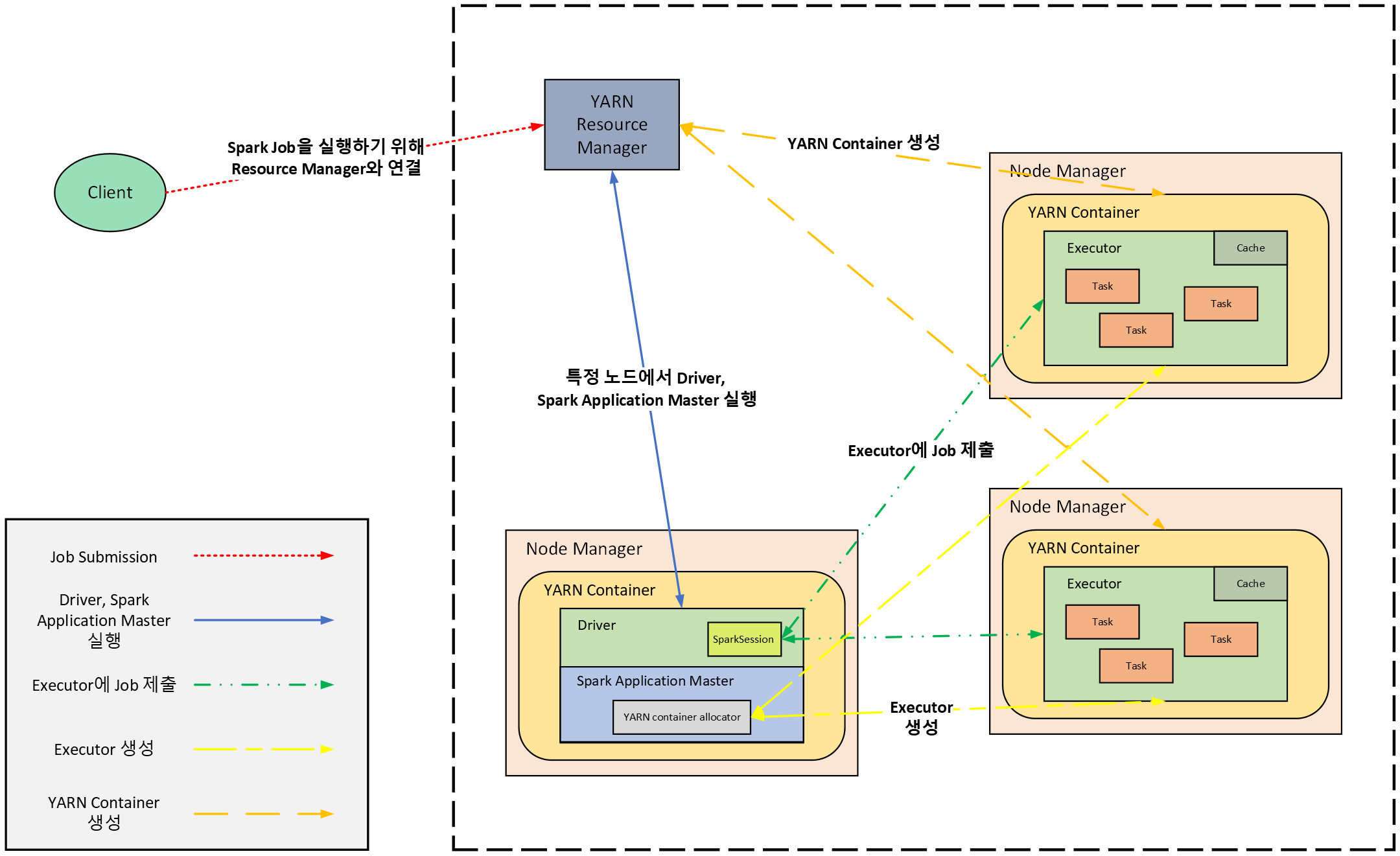
<그림 3> Spark on YARN 클러스터 아키텍처
트러블 슈팅 과정에서 에러가 발생하는 이유를 이해하기 위해, 일주일 정도 에러 로그를 확인하고 테스트하고 롤백하기를 반복하며 실험을 진행했습니다. 또한, 아키텍처 및 동작과정을 이해하기 위해 여러 레퍼런스를 읽고 탐구했습니다.
프로젝트 결과
본 프로젝트를 통해 고가용성이 보장되는 분산파일시스템 Hadoop HDFS에서 Spark를 활용하여 데이터 분석을 수행할 수 있는 환경을 구축하고, Zeppelin을 활용한 Web기반의 Notebook을 사용해 데이터분석 코드를 쉽게 작성할 수 있는 환경을 구성하였습니다.
프로젝트를 통해 배운점
하드웨어 구매부터 시작하여 하둡 고가용성 클러스터 구축까지 전반적인 과정을 혼자서 해결하기 위해 부단히 노력한점도 있지만, 주위 분들의 의견과 도움이 있었기 때문에 제가 좀 더 빨리 에러를 찾고 해결할 수 있었던 것 같습니다. 이러한 과정에서 폭넓은 이해 및 문제해결 능력을 많이 키울 수 있었던 것 같습니다.
한계 및 개선방향
인프라 환경을 구성하였으나 이를 활용한 실질적인 프로젝트의 경험이 부족하다는 점이 본 프로젝트의 한계로 생각됩니다.
이런 대규모 데이터처리 환경을 위해 Hadoop, Spark 뿐만이 아니라 Kafka, … 등 여러 에코시스템을 함께 활용할 필요가 있습니다. 또한, 복잡한 분산 환경을 관리하기 위해 모니터링 환경을 구성하여 관리할 필요가 있다고 생각합니다. 개인으로 진행하여, 이런 부분에서 미숙하고 부족하다는 점에 아쉬움이 많이 남으며, 향후 실무에서 팀단위로 데이터 처리 환경을 구성하고 활용하는 경험을 해보고 싶습니다.
